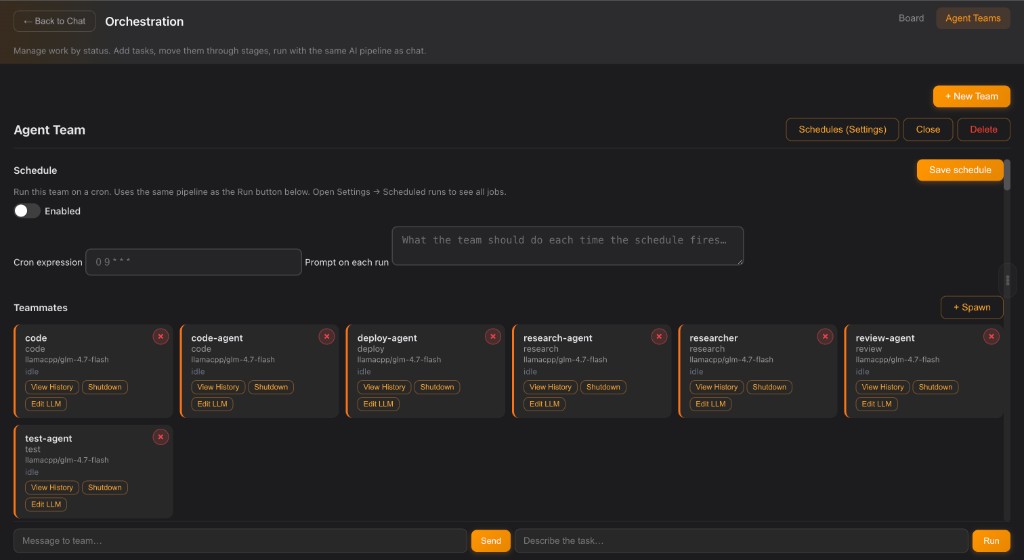
Orchestration layer
Route tasks across expert models, tools, channels, and human approvals.
Enterprise multi-agent AI
AAA AI turns complex questions into verified, structured action—across web, iOS, and desktop.
Connect the providers and runtimes your team already trusts, from private local models to frontier cloud intelligence.







Supported platforms and deployment ecosystems. Logos do not imply commercial endorsement.
Work
Bring reasoning, context, tools, and human judgment into one operating loop.
Platform
A unified foundation that gets more useful with every deployment.
Route tasks across expert models, tools, channels, and human approvals.
Ground every agent in your memory, documents, policies, and processes.
Choose local Ollama runtimes, cloud APIs, or the right mix for each task.
Observe runs, enforce roles, review decisions, and keep a clear audit trail.
Deployment
Run AAA AI close to your data, connect to the cloud when it helps, and change the mix whenever your needs change.
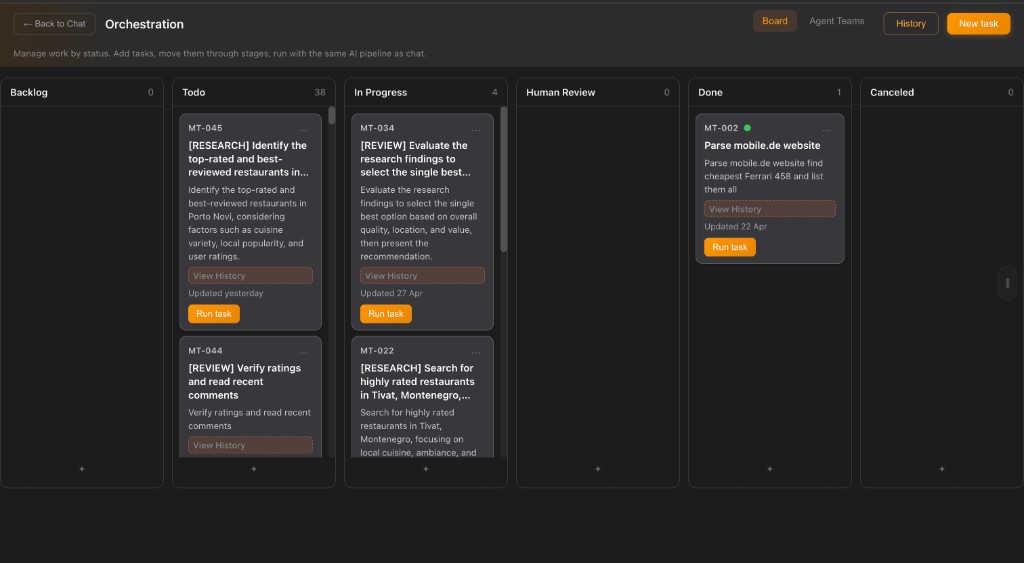
Coordinate agents, teams, and work across every runtime.
Keep sensitive workflows on hardware you control.
Use frontier models selectively without rebuilding your workflow.
Carry memory and policy across models instead of locking them inside one vendor.
Across the organization
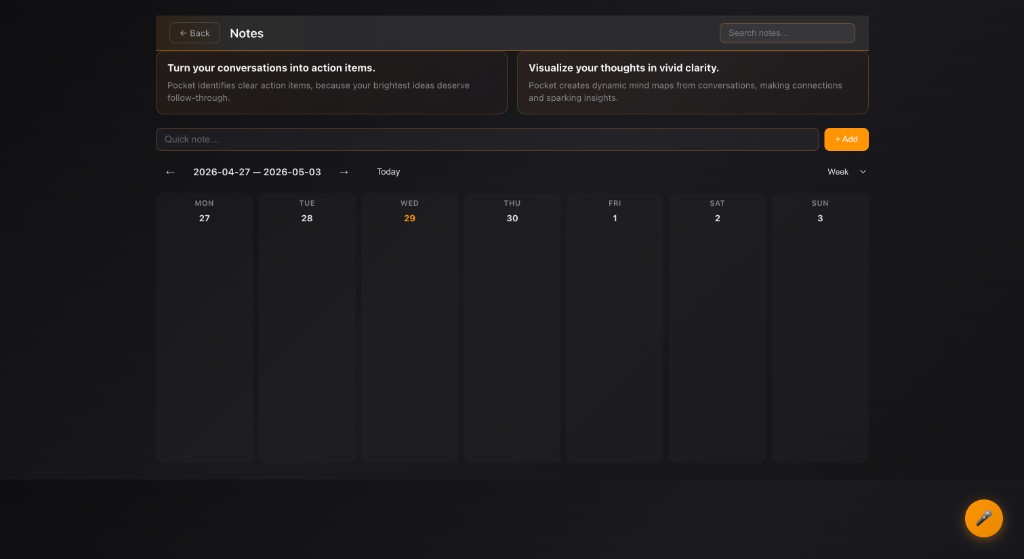
Turn meetings, notes, and documents into living context agents can use.
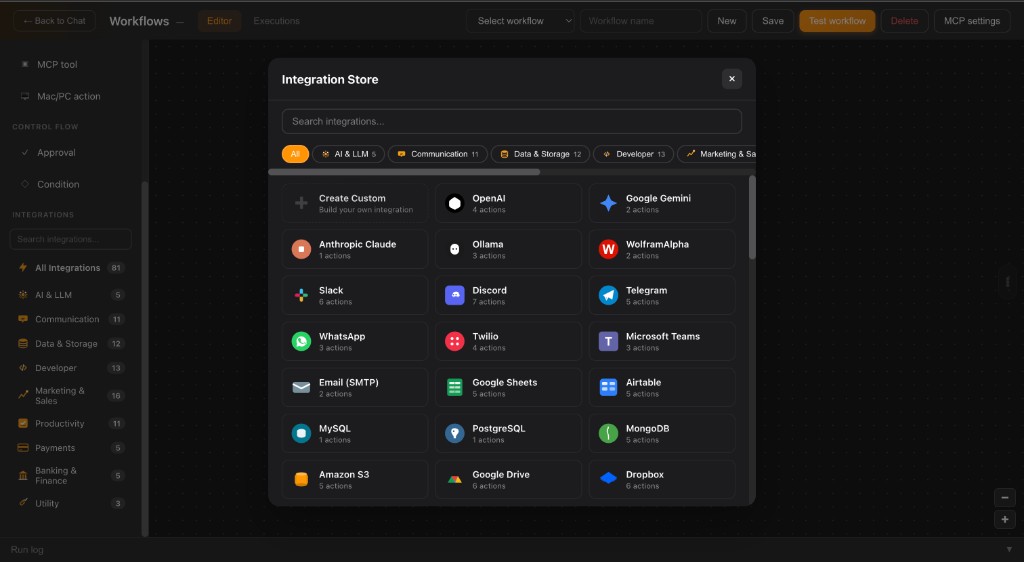
Connect models, data, messaging, and business systems without rebuilding the core.
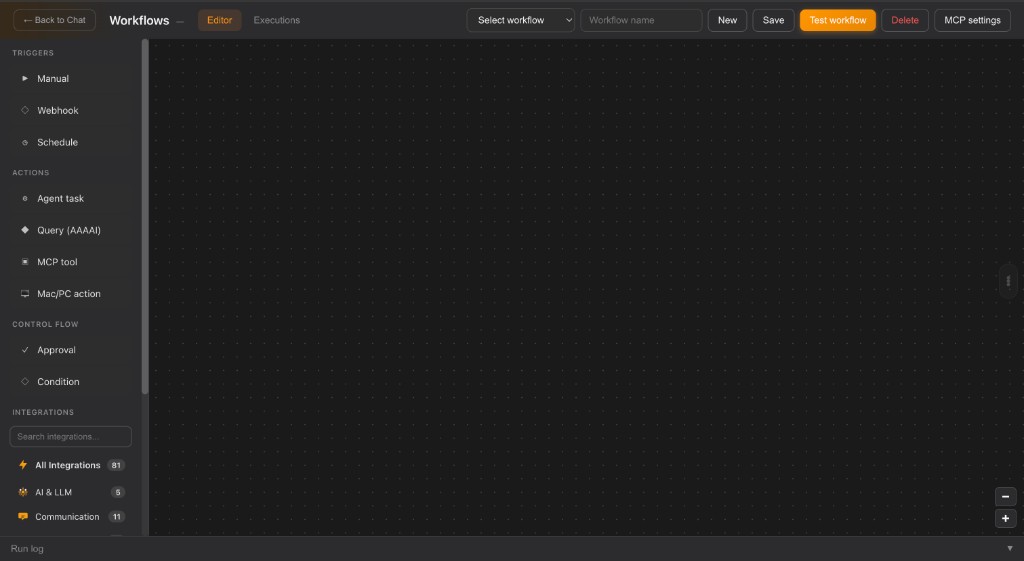
Automate multi-step work while keeping approvals exactly where they belong.
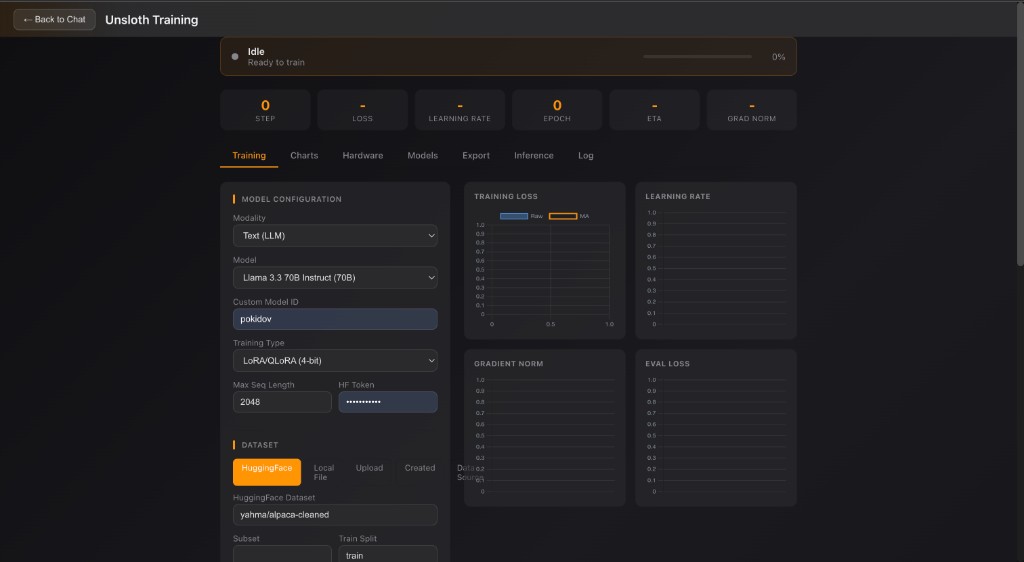
Train, evaluate, and route specialized intelligence for your own domain.
Control
The controls modern teams need to deploy agentic work with confidence.
Customer-controlled deployment, data boundaries, and model access.
Trace agent runs, intermediate decisions, tool calls, and outcomes.
Put review, permissions, and escalation into every critical workflow.
Produce decisions, documents, and structured artifacts—not endless chat.
Designed to support customer-controlled compliance programs
Start now
Begin with one team. Keep the architecture ready for the whole organization.